DreamHuman: Animatable 3D Avatars from Text
[Paper] [BibTeX] [Avatar Gallery] [Animation Gallery]
[Paper] [BibTeX] [Avatar Gallery] [Animation Gallery]
We present DreamHuman, a method to generate realistic animatable 3D human avatar models solely from textual descriptions. Recent text-to-3D methods have made considerable strides in generation, but are still lacking in important aspects. Control and often spatial resolution remain limited, existing methods produce fixed rather than animated 3D human models, and anthropometric consistency for complex structures like people remains a challenge. DreamHuman connects large text-to-image synthesis models, neural radiance fields, and statistical human body models in a novel modeling and optimization framework. This makes it possible to generate dynamic 3D human avatars with high-quality textures and learned, instance-specific, surface deformations. We demonstrate that our method is capable to generate a wide variety of animatable, realistic 3D human models from text. Our 3D models have diverse appearance, clothing, skin tones and body shapes, and significantly outperform both generic text-to-3D approaches and previous text-based 3D avatar generators in visual fidelity.
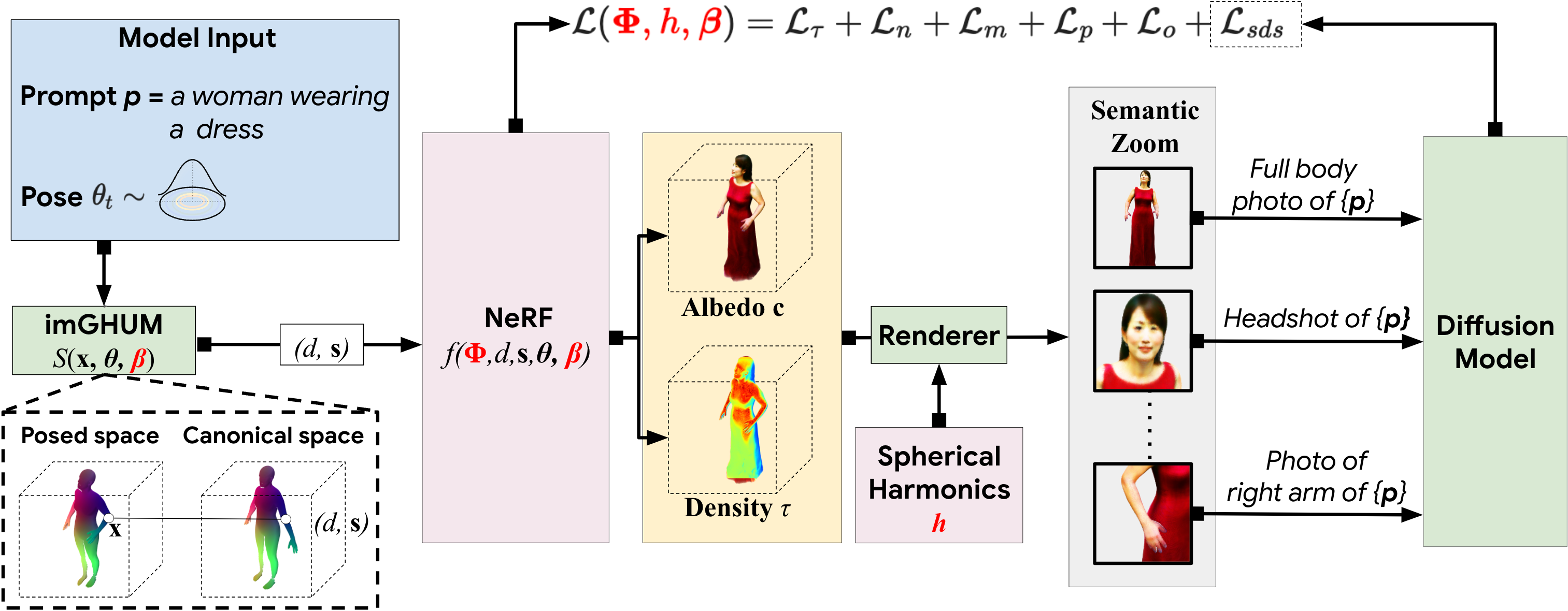
Given a text prompt, such as a woman wearing a dress
, we generate a realistic,
animatable 3D avatar whose appearance and body shape match the textual description.
A key component in our pipeline is a deformable and pose-conditioned NeRF model learned and
constrained using imGHUM, an implicit statistical 3D human pose and shape model.
At each training step, we synthesize our avatar based on randomly sampled poses and render it
from random viewpoints.
The optimisation of the avatar structure is guided by the Score Distillation Sampling loss
powered by a text-to-image generation model.
We rely on imGHUM to add pose control and inject anthropomorphic priors in the avatar
optimisation process.
During training, we optimise over the NeRF, body shape, and spherical harmonics illumination
parameters.
Here we show 360 renderings of our generated 3D avatars for a variety of text prompts. For additional results, you can look at our Avatar Gallery.
Here we show short animations using our model for different text prompts. For additional results, you can look at our Animation Gallery.
@article{kolotouros2023dreamhuman,
title={DreamHuman: Animatable 3D Avatars from Text},
author={Kolotouros, Nikos and Alldieck, Thiemo and Zanfir, Andrei
and Bazavan, Eduard Gabriel and Fieraru, Mihai and Sminchisescu, Cristian},
booktitle={NeurIPS},
year={2023}
}
Acknowledgements: This website was based on DreamBooth, DreamFusion, and Ref-NeRF.